本文提出了一种新的条件像素合成模型,并在物体计数这个下游任务中有关键优势
related works
我们提出了一种像素合成模型,它学习了一个有条件的 2D 空间坐标网格以及连续的时间维度,这对遥感应用很合适,因为同一位置可以由不同设备(如 NAIP 或 Sentinel-2)在不同时间(如 2016 年或 2018 年)捕获。
problem set
输入:我们给定了同一位置的高分辨率(HR)和低分辨率(LR)两个时间序列。直观地说,我们希望利用 HR 图像中丰富的信息和 LR 图像的高时间频率,以获得两者的最佳效果
输出:某时刻 t 的 HR
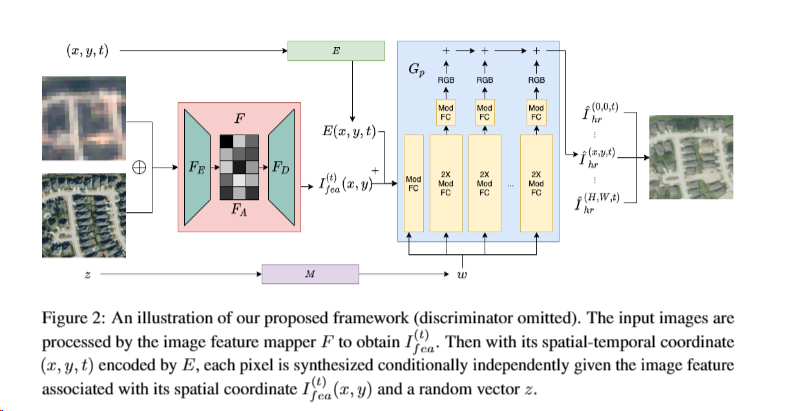
method
图像特征映射器(Image Feature Mapper)
首先对低分辨率图像进行最近邻重采样,得到拼接后的输入图像 I_cat(一层 HR,一层 LR,2C x H x W)
使用邻域编码器 F_E 和全局编码器 F_A 提取图像特征,得到特征图 I_fea(C_fea x H x W)
位置编码器(Positional Encoder)
使用傅里叶特征和空间坐标嵌入,得到位置编码 E(x,y,t)
像素合成器(Pixel Synthesizer)
根据 I_fea、E(x,y,t) 和随机向量 z,独立地合成每个像素值
具体来说,G_p 包含以下几个关键组件:
- 映射函数 g_z:
- 它将位置编码 E(x,y,t) 映射到一个 C_fea 维的向量。
- 这个映射函数帮助 G_p 学习如何利用位置信息来生成对应位置的像素值。
- 样式注入模块:
- 首先使用一个多层感知机 M 将噪声向量 z 映射到一个样式向量 w。
- 然后在 G_p 的多个全连接层中注入这个样式向量 w,以保持生成像素之间的样式一致性。
- 逐像素生成:
- 对于每个坐标(x,y,t),G_p 根据 I_fea(x,y)、g_z(E(x,y,t)) 和 w 独立地生成对应的像素值。
- 这种逐像素、条件独立的生成方式使得 G_p 可以并行高效地生成整张高分辨率图像。
使用多层感知机和样式注入的方式生成最终的高分辨率图像
- 映射函数 g_z:
对抗训练
引入判别器 D 进行对抗训练,以提高生成图像的质量