如何使用自定义的数据集训练自己的 control net:
ControlNet/docs/train.md at main · lllyasviel/ControlNet (github.com)
由于别的数据集都太大了,打算直接用先用 Fill50K 来试一下
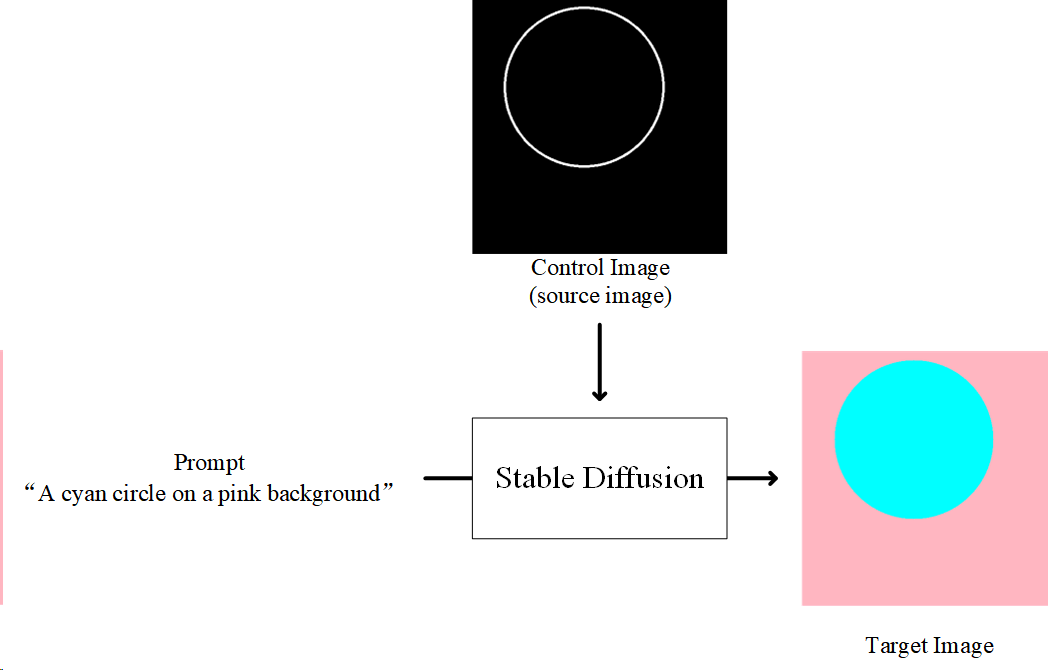
模型已经知道的:已经知道什么是“青色”,什么是“圆形”,什么是“粉红色”,什么是“背景”
不知道的:control image 的图像的含义
模型目的:训练模型使得其能够正确往圆圈和背景里填正确的颜色
首先下载,然后解压到
1 | ControlNet/training/fill50k/prompt.json |
接着测试一下有没有成功读进来:(使用 tutorial_dataset.py)
发现是可以读进来的
然后选择一个预训练好的 stable diffusion 模型:
runwayml/stable-diffusion-v1-5 at main (hf-mirror.com)
然后就可以使用
1 | python tool_add_control.py ./models/v1-5-pruned.ckpt ./models/control_sd15_ini.ckpt |
来将处理后的模型 (SD+ControlNet) 保存在“./models/control_sd15_ini.ckpt”位置
最后就可以开始 train 了
运行 tutorial_train.py
1 | import pytorch_lightning as pl |
发现 CUDA out of memory
查了发现 24g 的显存都爆了,只能把 batch size 设成 3,勉强够用。。。
最终运行了大概 1.3 个 epoch
效果:
按时间顺序从后往前排序
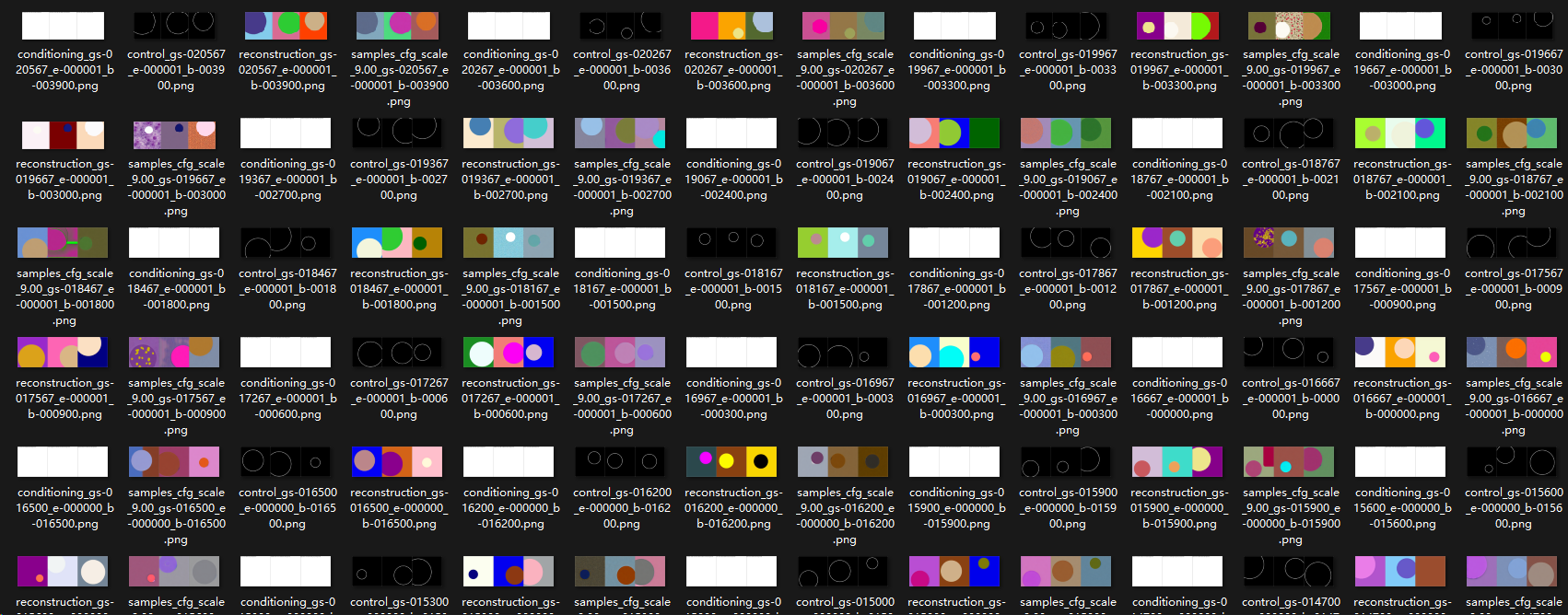
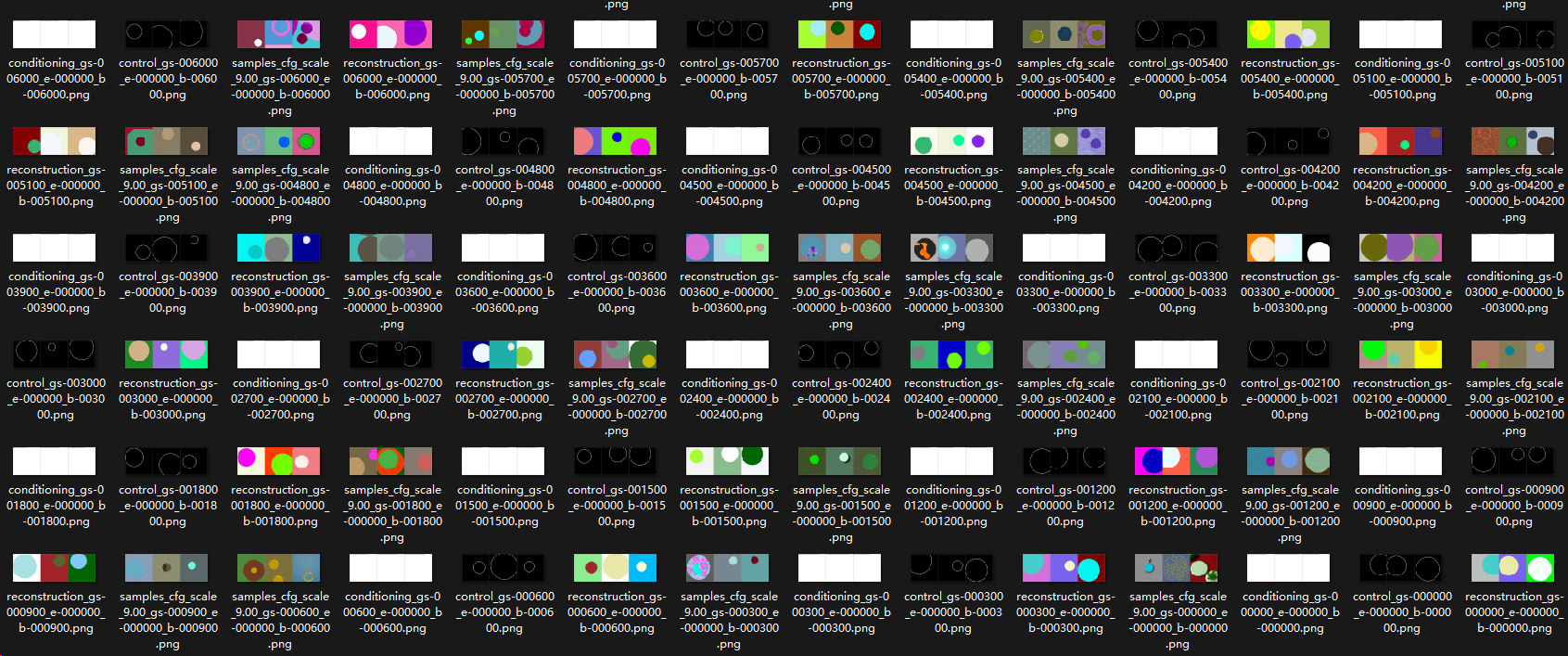
四个一组,分别是 prompt,input,ground truth, output
可以看到随着训练的增加,一开始的输出非常接近真实世界(权重都集中在原本的模型上),带有真实物体的花纹等等;后面无论是
- 填充的颜色
- 圆圈的位置和大小
逐渐能够接近 ground truth
证明训练是有效的
训练后的模型文件在 ControlNet\lightning_logs\version_0\checkpoints 中