CLIP
input:文字和图片的成对输入(一个正样本)
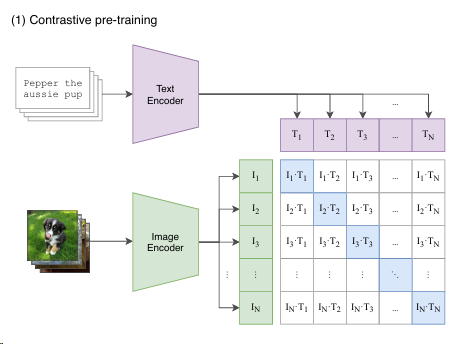
也就是说对角线上的都是正样本,其他都是负样本
没有分类头,如何分类
prompt template:
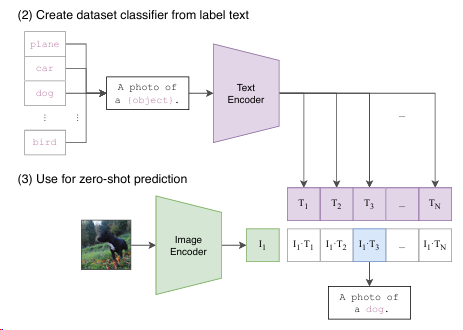
文本描述的准备:
- 对于每一个分类任务,首先需要准备一组文本标签,这些标签通常是对应于各个类别的描述性文本。例如,如果任务是对动物图片进行分类,文本标签可能包括“狗”,“猫”,“马”等。
文本编码:
- 使用 CLIP 的文本编码器将上述文本标签转换为高维空间中的向量。这些向量捕捉了文本标签的语义信息。
图像编码:
- 同时,使用 CLIP 的图像编码器将输入图像转换为同样维度的向量。这个向量代表了图像的视觉内容。
相似性比较:
- 对于给定的图像,通过计算其图像向量与所有类别文本向量之间的相似性来进行分类。相似性通常通过点积或者 cosine 相似度来计算。
- 图像被分类到相似度最高的类别。
pseudocode
1 | # image_encoder - ResNet or Vision Transformer |
编码器和输入数据
- image_encoder - 可以是 ResNet 或 Vision Transformer(ViT)。这些都是流行的图像编码器,用于从输入图像 ( I[n, h, w, c] ) 中提取特征,其中 ( n ) 是批次大小,( h ), ( w ), ( c ) 分别代表图像的高度、宽度和通道数。
- text_encoder - 可以是 CBOW(Continuous Bag of Words)或文本 Transformer。这些编码器用于从对齐的文本数据 ( T[n, l] ) 中提取特征,其中 ( l ) 代表文本的长度。
特征提取和投影
- I_f 和 T_f 分别是通过图像编码器和文本编码器得到的原始特征。
- W_i 和 W_t 是学习到的投影矩阵,用于将图像和文本的原始特征映射到共同的嵌入空间(维度为 ( d_e ))。
- 通过点乘和 ( L2 ) 归一化,将特征 ( I_f ) 和 ( T_f ) 投影到嵌入空间,得到 ( I_e ) 和 ( T_e )。
相似性计算和损失函数
- logits 通过计算 ( I_e ) 和 ( T_e ) 的点积并乘以温度参数 ( t ) 的指数,得到大小为 ( [n, n] ) 的相似性矩阵。这里的温度参数 ( t ) 调控相似性分数的尺度。
- labels 是一个自然数序列,用于交叉熵损失计算,表示每个样本的正确类别标签。
- loss_i 和 loss_t 分别计算图像到文本和文本到图像的交叉熵损失。
- 总损失 ( \text{loss} ) 是两个方向损失的平均。
模型训练和性能调整
- 训练了不同配置的 ResNet 和 Vision Transformer 模型。
- 对于文本编码器,主要调整模型的宽度,而不是深度,因为发现 CLIP 的性能对文本编码器的容量不太敏感。
zero-shot transfer
文本的多义性
比如 crane=起重机||鹤
所以就用一个 prompt engineering : 把单个的单词改为一个句子:”A photo of a {label}.”
可以很好解决这个问题
而且对于不同的任务可以换不同的模板,文中一共用了 80 个
对于难的数据集,few shot 更合理
毕竟人也不一定能分出来
downstream 用全部的数据不用 few shot:
为什么用 linear probe 不用 fine tune:
- 网络基本是冻住的,可学习空间小,这样本来预训练的模型效果不好的话,downstream 的模型效果也不会好
- 不怎么需要调参,fine tune 可调的参数太多了
- 本来就是要研究和数据集无关的预训练方式的
不足之处
通过加规模提点的代价很大
细分类的效果一般
不能处理特别抽象的概念(计数,区分监控视频是否异常等)
对数据的利用不高效
可以提供一些难以用语言描述的样本(有时候提供 1,2shot 还比 zero shot 差了,应该是说某些 prompt 提供的不太好?)
CLIP 相关工作
LANGUAGE-DRIVEN SEMANTIC SEGMENTATION
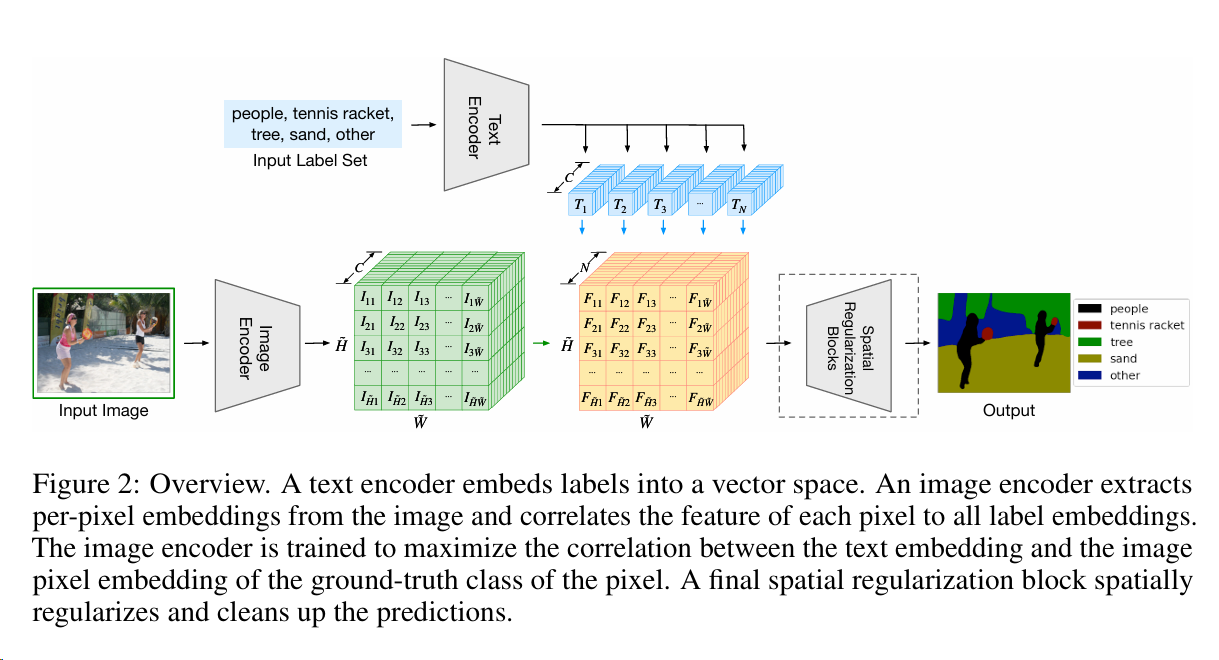
这里升维到 N 是为了进行后续语义分割的工作
Word-pixel correlation tensor(就是橙色的部分)
目标是最大化与地面真实标签 k=y{ij}对应的条目 (f{ijk}) 的点积
公式 2:
对于每一个像素位置(i,j)都能有一个 N 维向量,所以可以算一个 softmax 的输出,然后把这些输出加起来就可以得到每一维度的输出
GroupViT: Semantic Segmentation Emerges from Text Supervision
上一篇工作并没有把文本作为监督信号,如何做到,并做到无监督的训练?
这篇工作并不依赖于 segmentation mask 的手工标注,而是可以像 CLIP 那样利用 img-text 文本对,进行无监督训练
Group:总之是某种聚类?
能在学习的时候就能把相邻相似的像素点 group 起来,变成一个个的 segmentation mask
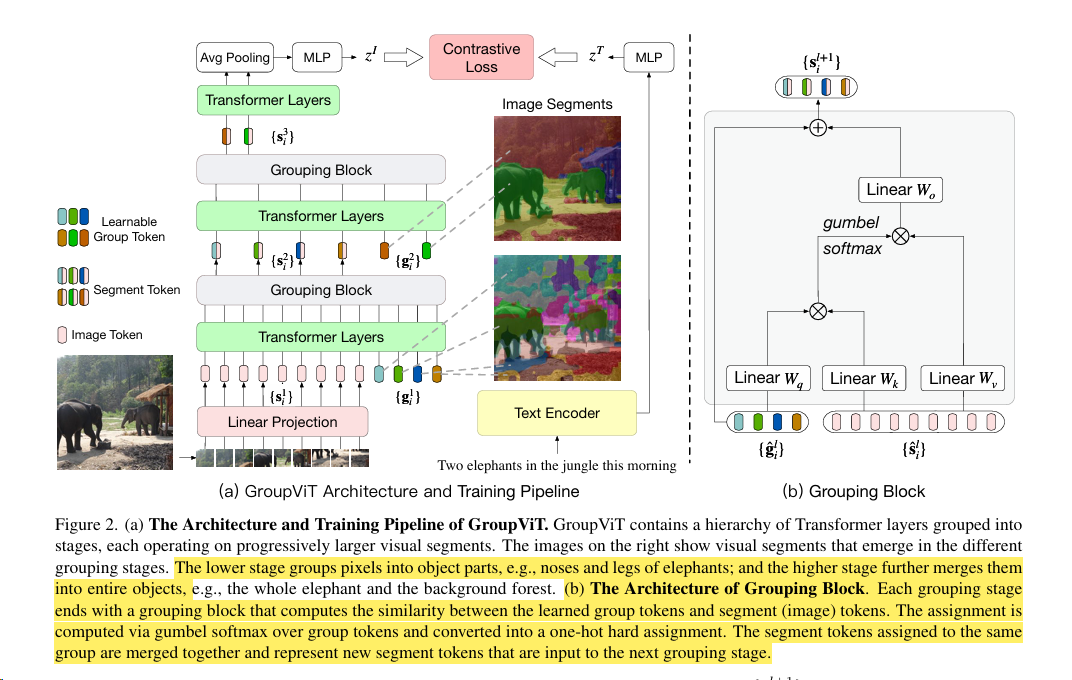
Grouping Block:这个块的主要功能是计算学习到的组标记(group tokens)与图像片段标记(segment tokens)之间的相似性。这一计算过程主要通过使用 gumbel softmax 来完成。
关于 loss:text 的 loss 和之前是一样的,但在 avg pooling 前面那一步,还是一个 8*384 的特征序列,所以要把 8 块特征融合到一块,pooling 之后再经过 MLP 就得到了一个一维的特征向量
问题:
- 依然是 CLIP 的问题:只能学到语义明确的东西(比如背景就是一个不明确的东西)
OPEN-VOCABULARY OBJECT DETECTION VIA VISION AND LANGUAGE KNOWLEDGE DISTILLATION
clip 作为教师,知识蒸馏自己的模型?
还不懂知识蒸馏是什么。。。
考虑图 1,我们能否设计出超越仅识别训练标签中存在的基本类别(例如,玩具)的对象检测器,并扩展词汇表以检测新的类别(例如,玩具大象)?在本文中,我们的目标是训练一个开放词汇的对象检测器,该检测器能够检测任何由文本输入描述的新类别的对象,仅使用基本类别中的检测注释。
怎么定位,怎么分类?这两个文中是分开来做的
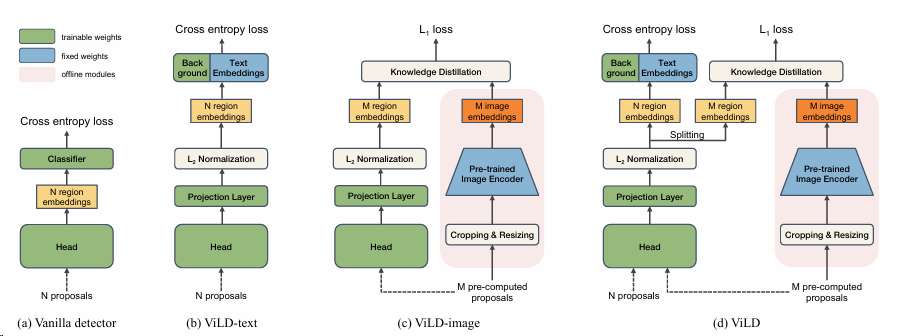
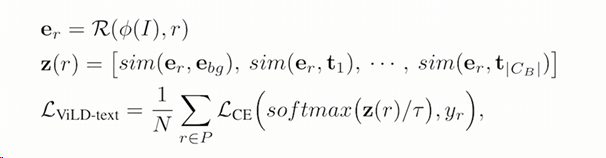
N 个 proposals 通过 RPN 得到(也就是物体可能存在的位置)
$e_r$是 reign embedding
z(r)是一个类似 logits 的东西
然后就能和 ground truth 算一个交叉熵了
在文中提到的“M pre-computed proposals”指的是预先计算好的候选区域(proposals),这些候选区域是在训练过程中或训练之前由区域提议网络(Region Proposal Network, RPN)生成的。这些 proposals 被用于后续的处理步骤,包括裁剪、调整大小,并通过预训练的图像编码器来生成图像嵌入。
在 ViLD 方法中,这些预先计算的 proposals 用于两个主要目的:
- ViLD-image:在这个组件中,使用预先计算的 proposals 来生成图像嵌入,这些嵌入随后与区域嵌入进行对齐,以最小化它们之间的距离(例如,使用 L1 损失)。这有助于确保检测到的区域在视觉上与分类模型中的相应类别相匹配。
- ViLD-text:在这个组件中,使用预先计算的 proposals 的图像嵌入与文本嵌入进行比较和分类。文本嵌入是通过将类别名称输入到预训练的文本编码器中生成的。
这些预先计算的 proposals 是在模型训练阶段之前生成的,通常是通过在训练集上运行 RPN 来实现的。这样做的目的是为了加速训练过程,因为这避免了在每个训练迭代中重复生成 proposals 的需要。这些 proposals 被视为固定输入,用于训练过程中的知识蒸馏和特征学习。
ViLD-text 做的是 img-text 的关联,然后就可以做 zero-shot 了(目前是在 basic class 上训练的,还没有 novel class)
右边是 teacher,左边是 student
没看懂,为什么不直接用 clip 的 encoder 做 region embedding 呢(胡言乱语)
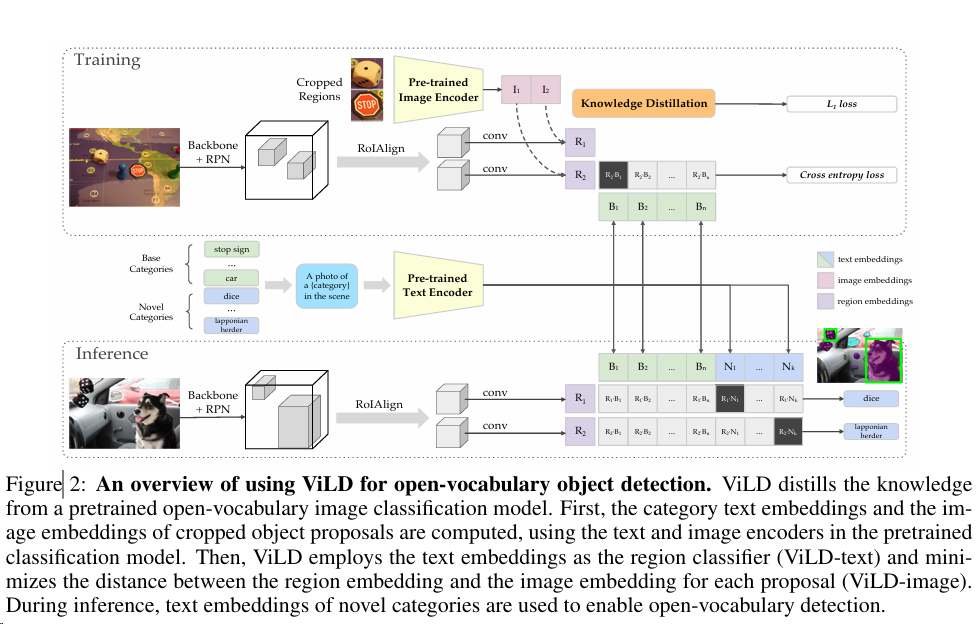
使用 ViLD 进行开放词汇对象检测的概述。ViLD 从预训练的开放词汇图像分类模型中提取知识。首先,使用预训练分类模型中的文本和图像编码器计算类别文本嵌入和裁剪对象提议的图像嵌入。然后,ViLD 使用文本嵌入作为区域分类器(ViLD-text)并最小化每个提议的区域嵌入和图像嵌入之间的距离(ViLD-image)。在推理过程中,使用新类别的文本嵌入来实现开放词汇检测。
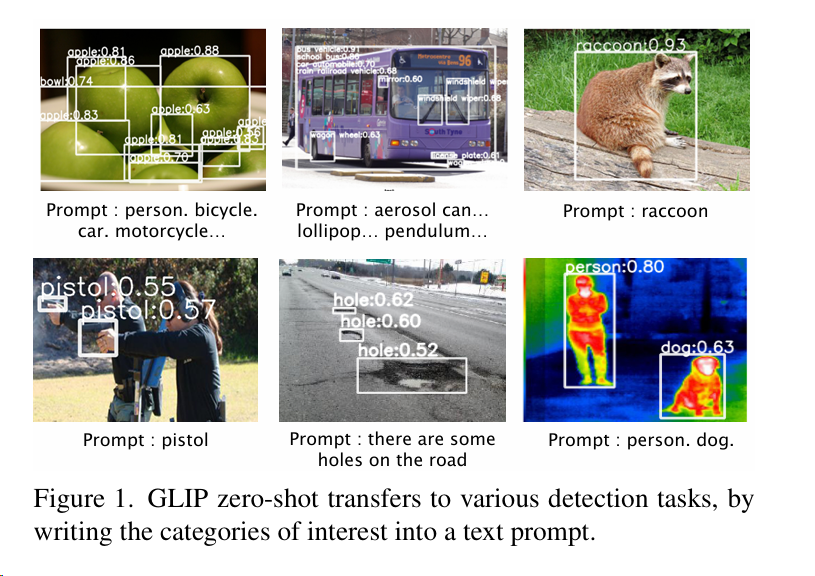
GLIP
CLIP 适用于分类任务,而 GLIP 尝试将这一技术应用于目标检测等更加复杂的任务中。
作者提出了 phrase grounding 的概念,意思是让模型去学习图片和句子短语之间更加精细的联系
loss=L 分类+L 定位
先看 detection

O 就是 N*d 的 region embedding,就是说有 N 个 bounding box,每个的维度是 d,然后后面接一个分类头,看每个 bounding box 里的物体是哪个类, c 是多少个类别,乘一下就能得到分类的 logits $S_{cls}$,然后和 ground truth 算一个 loss 就能算最终的分类结果了
再看 vision grounding

是通过算了一个$S_{ground}$ ,将目标检测重新定义为短语匹配(grounding)任务时使用的对齐分数
P 是输入 text 的 embedding,然后和 img 的 embedding 算一个相似度
也就是说,$S_{ground}$表示每个区域/框与每个短语之间的匹配程度,是我们重新定义的目标检测任务的核心输出,通过优化这个对齐分数,模型可以学习将图像区域与文本短语进行精准匹配。
这种统一的损失函数有两个好处:
- 可以同时优化目标检测和短语匹配两个任务,发挥两者之间的协同效应。
- 可以直接将训练好的短语匹配模型应用到任意目标检测任务上,实现零样本迁移。
总体框架
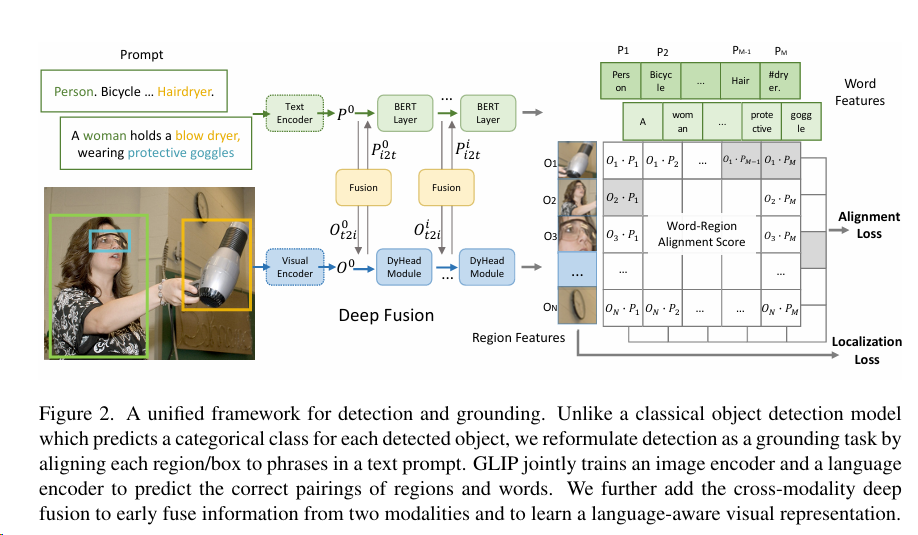
这里的 deep fusion 可以实现特征间的融合:
- 使用 DyHead 作为图像编码器,BERT 作为文本编码器。
- 在 DyHead 的最后几个模块和 BERT 的顶层之间,添加了跨模态多头注意力模块(X-MHA)。
- 这个 X-MHA 模块实现了图像特征和文本特征之间的交互和融合。
- 融合后的特征会再经过单模态的融合和更新,得到最终的语言感知视觉表示。
具体公式:
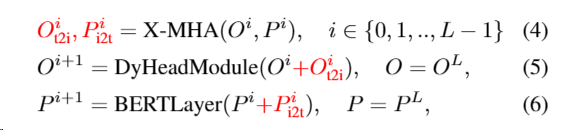
其中 O 和 P 分别表示视觉和语言特征,i 表示 DyHead 和 BERT 的层数。通过这种跨模态的深度融合,GLIP 可以学习到语言感知的视觉表示,从而提高在各种目标检测任务上的泛化性能